“有效搜集信息”是每一个生活在互联网中的现代人都应该拥有的重要技能。我没怎么写过这个话题,是因为我觉得这是个虽重要但并不复杂的技能,熟练使用互联网的人应该都略知一二吧。但我还是一而再再而三地发现,还真依然有太多人不知道如何搜集信息。所谓不会搜集信息,很大程度上体现在不知道如何判断眼前信息的价值上。
去年年底我在微博上搞了个 #AskMeAnything 的活动,其中很多问题集中在职业选择职场规划上。当然,所有人都想知道什么行业在未来会持续走上坡路,蓝海和风口在哪里,在欧洲什么职业吃香,在国内什么工作值得跳槽。但你若直接问网络上一个陌生人他对此的看法,这种信息的价值很低——一方面取决于回答人是谁,但大概率上来说,这种信息的价值对你个人来说确实很低。虽然价值低,但这么做的人却永远络绎不绝。
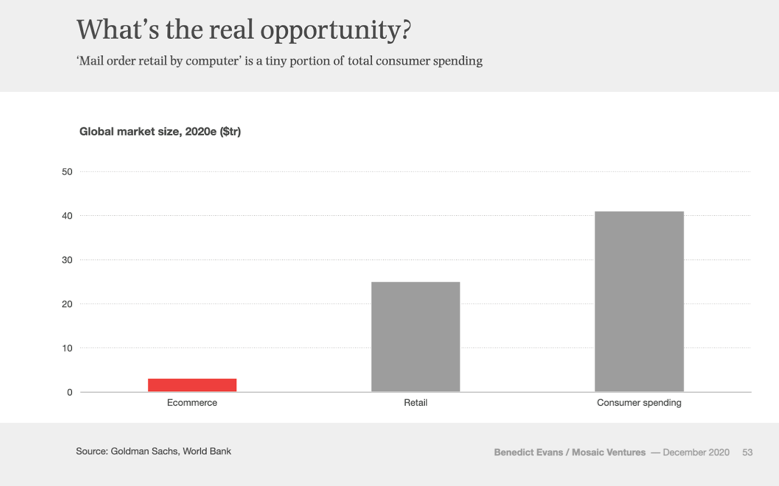
这里我就想举另一个相反的例子。前几天我在微博上分享了一份新鲜出炉的行业报告,主题是 European Unicorns(欧洲独角兽)。这份报告集结了很多可信度高的行业数据以及作者本人(一个在咨询分析和科技风投行业从业二十年的行家)的总结和看法。但这条微博却鲜有人点赞评论。然而其中的价值呢,绝对超越社交网络上99%的碎片内容。
比如,这篇报道指出,近年来全球风投和初创科技公司开始不再像过去一样高度集中在硅谷,在去年,欧洲筹集到种子期投资的初创公司数量已达美国数量的70%。截至去年,欧洲已经出现120个以上估值过一亿美金的独角兽公司——十年前,这个数字还是个位数。
欧洲电商和网络营销(online advertising)的发展还大大落后于美国,说明这两个行业在欧洲还处于起步阶段,未来很可能会迎来快速、长线发展。
报告还指出欧洲科技公司具有优势的三个行业:前沿科学(frontier science)、金融科技(fintech)、生物。

对于一个计划或已经来欧洲留学、工作的人,这些信息得多有价值啊。这样公开、免费、准确、前沿的行业报告,却是放在普通读者面前都不怎么会去问津的信息。到底是为什么呢?
这样一份行业报告的比社交网络上一条职场问答碎片价值高是显然的事,但我们不妨花两分钟来分析一下为什么有的信息价值高,有的信息价值低。明白原理后才能更好地降低自己以后视价值而不见的概率。
道理很简单:离“源头”越近的信息,价值往往越高。拿科研领域的一条信息传播链举例:在实验室里通过科学方法验证的一个科研假说,就是处于源头的信息。论文是其载体。往下走,加工一手科研论文信息的包括文献综述、一手行业报告和专业书籍,再把综述和行业报告选择性翻译传播给大众的有大众媒体和通俗图书。再往下游走,社交媒体上传播的往往是对媒体专业记者所写内容的再加工。最后还可能下沉到完全无法回溯信息源的形式,比如”我听村口老大爷说……“。这个信息下沉的过程持续数十年也不少见。
从这儿很容易看出,离创造信息的源头越远,这条信息的精确性就越低,前瞻性越差,价值也是由高向低走,到最后可能就完全没有任何价值可言。表面上看,信息依靠一级级的物理载体(论文、书籍、新闻报纸、人口)向下传播。实际上,最初提取拼凑信息的和中间不断解读加工信息的本质上都是人脑。人脑活动对外不可见,有的人脑加工解读信息的过程中联想了更多信息,更多人脑连准确全面的阅读理解都做不到。选择将加工后信息继续传递下去的人脑还各有各的目的,有意选择性甚至歪曲原意传递信息的也不在少数。
所以这个过程就像”传话“游戏一样,即使中间环节的人脑都怀着尽力传递准确信息的态度(现实场景中这基本不可能)传播信息,信息的变形和衰减无法避免。链条越长,衰减越厉害。因此,当面对信息时,不妨从”距源头有多远“的角度来判断此信息的价值。当你站在信息源头,甚至自己尝试根据已知条件才拼出一条信息时,你获取的信息对未来行动的参考价值可能辐射长达数年甚至数十年。但你若站在信息食物链的下游的下游的下游,轮到你消费时,确实只能剩下渣渣了。