进入互联网时代后的现代社会是个信息的时代,现代人所追求的大部分东西都可以被看作是一种信息编码。长期来看,获取有效信息的能力和输入信息的质量对个人境遇的影响会越来越大。一是因为时间所带来的复利效应;二是信息时代的信息总量会不停膨胀,但优质信息总是相对稀缺的,所以过滤的难度会变大;三是因为以初级人工智能算法为基础设计的推荐系统是个信息回音壁,算法喂给用户的内容是为了调动原始情绪而非提升思维,所以无法主动搜集获取有效信息的人,可能会在机器学习算法的调教下越来越蠢……
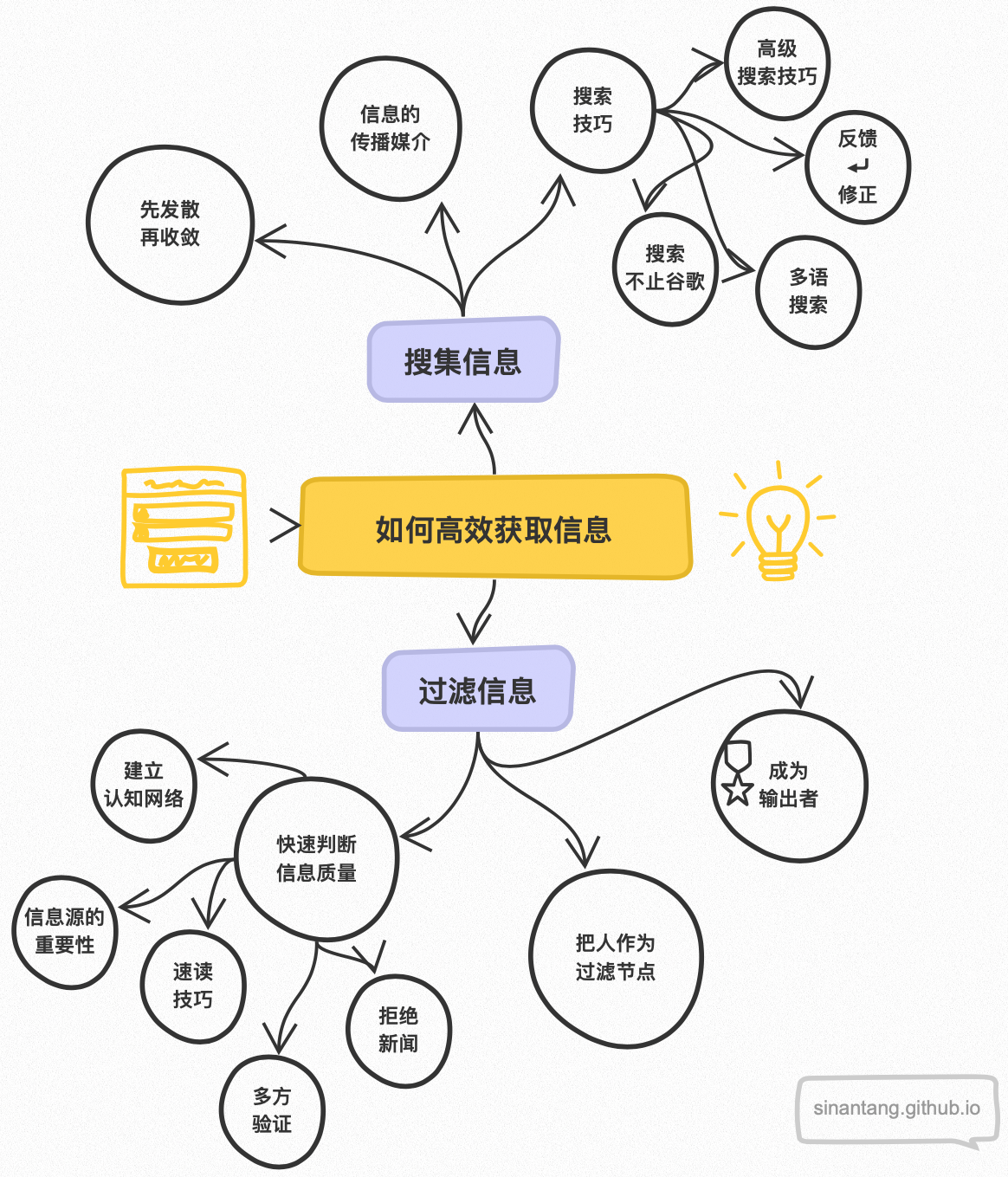
那该如何主动获取有效信息,提高输入信息的质量呢?我想在这篇文章里记录一下现阶段我对这个话题的思考结果,分为“搜集信息”和“过滤信息”两大部分。
搜集信息
先发散再收敛 Diverge before converge
「Diverge before converge」是设计思维(design thinking)里借用数学概念的一条思考原则,即在解决问题时,先发散思维把所有能想到的选项都列出来,再进入筛选、优化、决策阶段。这里特别反对的(但大多数人会自动采取的)方法是面对问题时,沿着最小阻力路径,草率采用眼前的第一个选项。
作为反面例子,不知道有多少人记得《老友记》里有这么一集:钱德勒辞职后想要换个全新的职业方向,莫妮卡借机整理了一整套职业选项分析系统让钱德勒参考。当莫妮卡按首字母排序刚念到第一个择业方向 Advertising 时,钱德勒就立即跳起来表示,就是这个了!若不谈戏剧效果,只看钱德勒在职业规划这件大事上的决策过程,他的做法确实是大忌。

这条原则同样适用于搜集判断信息。我曾在网上看到有人总结以下等式:
海量的正确信息 + 正确的思考方式 = 正确的答案;
少量的正确信息 + 正确的思考方式 = 不错误的答案;
海量的正确信息 + 错误的思考方式 = 不错误的答案;
少量的正确信息 + 错误的思考方式 = 错误的答案;
这其中影响因素的优化难度与其影响程度是不对称的:收集足够信息的难度远远低于优化思考方式的难度,但它对结果的影响却是巨大的。因此,不论对什么人来说,先尽可能收集到足量的信息都是第一步。当收集到足够多的正确信息(“正确”这一点下面会写到)后,任谁来做判断也出不了太大问题。 这可能也是为什么CEO的工作本身难度不大(不看责任承担),因为呈现到CEO面前的信息质量已足够高,此时作出正确决策对智商的要求并没有普通人想象得那么高。
具体来说,当我们开始搜集信息时,需要抑制住过早下结论的本能冲动,同时有意识地去搜索多方的论点和论据。比如,在考虑要不要出国留学时,不能百分百只接收出国多么好,留学多么有用这类信息,也要刻意搜索些不支持出国留学的信息,否则我们收集信息的过程又成了绕着回音壁转圈圈,不断强化自己的预设结论的过程。
理解信息的多种传播媒介
媒介是信息的一部分,信息存在多种传播媒介,如文字、图片、音频和视频;我想再加上一项“数据”,因为信息时代的很多信息存在于大数据之中,了解数据的呈现特点和数学含义是一项值得单独列出的技能。
不同媒介的特点不同,同一条信息以不同方式呈现时的信息传递效率也非常不同。比如,同样的信息以文字传播的信息密度远高于以视频传播的信息密度,大数据以图表可视化形式呈现所提供的认知效率远高于用文字描述,有些抽象概念用图像阐述的传播效率高于只用文字描述。
因此,在搜集信息时,需要考虑到不同的传播媒介。根据信息的性质来选择最合适的传播载体,大概率会提高我们的认知效率。
互联网搜索技巧
这一节列举了一些能快速提高通过搜索引擎收集信息效率的技巧合集。
“高级搜索技巧”
即通过特定语法来提高搜索准确性的技巧,如给关键词加引号不让搜索算法将词拆分开,用加减号提前过滤搜索结果等等。具体的就不列举了,去搜“高级搜索技巧”就能找到这些为更高效使用搜索引擎设计的简单语法。
通过反馈修正提问
很多人使用搜索引擎效率低的原因在于,他们其实并不知道自己该问什么,或者找不到正确的关键词。这种情况下最好的办法可能也只有不断地进行“反馈-修正-反馈-修正”的循环,尝试用不同方式来问同一个问题,换用不同关键词来指代同一个概念,缩小搜索范围或扩大范围……
学习搜索的过程其实也是在学习如何提问。
多语搜索
这也许是会说一种以上语言最实用的优势之一:搜集信息的效率比单语者高出N倍!
最有用的搜索语言是英语,因为英语是互联网上使用最广的语言,所有优质信息几乎都是英语的或存在英译版。我搜到一个 W3Techs 的统计数据,互联网上排名前一千万位的网站,其中 63.4% 都是用英语作为主要语言,所以学会用英语进行搜索可能是最快提高信息检索总量的方法。

除英语外再加一两种其他主要语言,会使搜索效率更高。比如,我经常会在中英文两种搜索结果中跳来跳去。有些抽象概念我理解不好英语,就会看一下中文内容辅助理解;有些技术概念我理解不了中文(因为往往是由英语翻译过去的),就会跳到英文网站搜一下结果;有时连德语也会派上用场,因为很多与德国相关的内容只有德语搜索结果,加之德语版的维基内容也比较丰富。
这里附赠一个我搜多语信息的小窍门:同时用“英语概念 + 一个中文词语”作为组合关键词(如“convergence 数学”、“deep learning 什么”)进行搜索,可以得到该英语概念的中文搜索结果。因为汉语文字信息密度高,加上对母语的阅读速度最快,所以中文搜索结果只要扫一两眼就能了解大概,再详细的信息可以转换到英语的搜索结果。很多时候这对我来说是了解陌生概念速度最快的方式。
比谷歌更专门化的搜索站点
谷歌是默认的综合信息搜索引擎,但并不是所有专业、非主流信息都能出现在谷歌搜索的前两页上,还有些专门化网站可以提供比谷歌更具针对性的信息或信息呈现方式更准确易懂的功能,比如 WolframAlpha 擅长计算绘图、数学概念分析、数据可视化,Internet Archive 可以用来搜索现在已经不存在的网页,谷歌学术专门用来检索论文和学术著作,你所在国家地区的图书馆检索系统除了能搜索到馆藏书籍外,很可能还能搜到历史期刊新闻与其他电子学习资源。
除了以网页文本为主的搜索外,目前以其他媒介传播的信息搜索难度很大,比如播客节目的具体内容、视频里的对白,这些信息默认是无法被检索到的。图书内容和图片的搜索,有一部分已经被谷歌(Google Books、Google Images)涵盖了。
过滤信息
没有信息过载,只有过滤失败。
—— Clay Shirky
快速判断信息质量
尽可能搜集到足够多信息的这个前提紧接着会给很多人造成下一个困难:收集了但浏览起来太慢或者根本看不完啊,又或者面对一条信息无法判断真伪或其价值。我认为这两个表相问题其实是同一个问题。解决起来的思路也是一致的——
建立基本的认知网络
快速判断一条信息质量的能力依赖于更底层的认知能力和知识网络,比如懂得基本的知识论(epistemology,探讨知识的本质、起源和范围的一个哲学分支)概念,理解基础科学研究方法,大致了解想要搜集信息的领域的认知框架。当一个人这些全都不懂时,就很难快速看懂那个领域的资料,或者以为自己看懂了实际上理解得南辕北辙。
在这种情况下,维基词条通常是最好的入口。
理解信息源的重要性
一年多前我写了一篇文章《信息食物链》,主要写的是信息分三六九等,类似能量在食物链中的传播模式,信息也在一级级地传播,经过传播的环节越多,损耗就越大。所以判断信息价值的原则之一是看它的原创度有多高,离“源头”有多近。
拿科研领域的一条信息传播链举例:在实验室里通过科学方法验证的一个科研假说,就是处于源头的信息。论文是其载体。往下走,加工一手科研论文信息的包括文献综述、一手行业报告和专业书籍。再把综述和行业报告选择性翻译传播给大众的有大众媒体和通俗图书。再往下游走,社交媒体上传播的往往是对媒体专业记者所写内容的再加工。最后还可能下沉到完全无法回溯信息源的形式,比如”我听村口王大爷说……“。
这个信息下沉的过程持续数十年也不少见。
除了原创度外,作者本身也是判断信息价值的重要因素。互联网上的信息浩如烟海,根据内容创作者的背景资历和过往记录来判断信息的可靠性,是效率较高的方法。比如,一个没有医科学历的人开口给专业医学问题下结论,一个不表明学历职业背景的人喜欢谈论专业度很高的话题,一个人全能到什么话题都要掺合一下,一个人喜欢脱离概率下绝对化的结论,一个人擅长拿边角料新闻或引用结论不可重复的某篇论文来支持自己的阴谋论,以上这些都是可以“一票否决”某个信息源的警告信号。
当你在信息食物链上越爬越高时,那些价值低甚至为负的垃圾信息源对你来说就会变得非常明显,都不必费力去一一分辨。
有效且快速的阅读技巧
我曾在一个讲如何读英语论文的视频里提过英语非虚构论述文的通用阅读方法:标题 -> 摘要 -> 结论 -> 所有小标题 -> 每节第一段 -> 每段第一句话。这是因为英语非虚构论述文的结构是非常固定的“总分总”结构,优秀论述文全文最重要的信息必然出现在开头(摘要)和结尾(结论),每一节最重要的信息会出现在第一段和最后一段,每一段最重要的信息位于第一句话。这就给了读者一个快速阅读掌握重点的固定方法。这个方法几乎可以推广到所有英文非虚构读物上。
因此当我们在搜索引擎里根据标题和提要点开了10个也许有用的网页时,高效的浏览方式是先按以上方法把所有页面上的要义快速浏览一遍,接着再细读其中几个最相关的网页内容。这个阶段最好不要一开始就在10个搜索结果中的第一/二条内容上花太久细看其中的每一句话,那样会很容易被锚定效应影响。大脑被先入为主的看法占据后,就更难为更多不同观点腾出认知空间。
真实信息可以通过多方印证
真实信息通常不怕被考验,所谓”真理越辩越明“。骗子才会怕你把他说的话去和其他信息源进行相互验证。当一条信息能被多个可以采信的信息源验证时,它的真实性会大幅上升。
这里的一个难点在于,很多人虽然也有验证信息的天然习惯,但他并没有通过可靠的信息源去验证,而是根据“一个(普通)同事说…”、“某个(其貌不扬的)亲戚说…”、“网上某个(不能验证真实身份的)网民说…”来相互验证——多个个体的认知偏差汇集在一起,也依然是认知偏差。
拒绝即时摄入热点新闻
还有一个过滤信息的简单方法就是拒绝即时摄入热点新闻。没法完全拒绝的话也应该尽量限制这方面的信息输入。因为新闻里的信噪比非常低,社交网络上传播的热点新闻又常常是为调动观众情绪,抑制理性思考的话题,比传统媒体发布新闻的信噪比还低。
自几年前起,我就在微博上取关了所有新闻类账号以及天天转发评论新闻的号。我并没有因此错过真正重要的事件,更重要的是我保留了上网时的认知资源给信噪比更高的内容。
把人作为更高效的信息过滤节点
内容创作者作为信息源的一个重要组成部分,实际上充当了信息过滤节点的角色。除了直接创作内容外,在网上转发、推荐其他内容自然也是一种帮读者过滤信息的行为。审慎选择可以充当自己信息输入节点的人,长期来看,这一点对个人认知能力和决策水平的影响,远高于大多数人的预设。
除了以上这种把人作为信息过滤节点的形式,在生活中还有另一种重要的信息搜集过滤方式,即主动与他人连接沟通。此时的沟通形式可以笼统地用 informational interview 来代指。这更适合信息聚集在相对小众、局部、不透明、存在壁垒的位置的状况,比如,某小众行业在某一城市的发展情况,如何联系到靠谱人脉出版一本书,一家中小型公司或者团队值不值得加入,如何进入一个新兴行业,公司遇到棘手问题如何解决。这些问题的真实答案很难通过普通的网络检索获取,但毫无疑问世界上一定有不止一人对这些问题比自己要了解得多。
美国作家 William Gibson 有一句名言,「The future is already here – it’s just not very evenly distributed.」(未来已来,只是分布得还不太均匀。) 这句话存在一个很妙的解读:我们未来要做出决策的信息来源,极有可能此时此刻已经存在了,只是分布得不均匀,需要一定的信息搜集、判断能力。通过 informational interview 把人(脑)作为信息筛选的节点,是一个在特定场景下收集有效、真实信息的好方法。
成为优质信息的输出者
最后这一条算是高阶技能,适合有志之士。
持续输出优质内容,成为信息源头的好处多多——
- 内容输出者熟悉信息传播的特性和规律,因此更容易鉴别外界信息的真实性与可靠度。
- 持续输出者自己可以成为一个汇聚信息和观点的节点,降低了错过领域内重要信息的概率,提高了阅读筛选信息的效率。
- 持续输出好内容的行为会吸引其他创作者和读者,因此能够靠近更多高质量的信息输入源。
把持续输出作为过滤信息的方法,也许是高效获取信息的终极制胜手段。
小结